

With the advent of large language models, large collections of text are more crucial than ever nowadays, and PDFs are abundant and important sources of Maltese text. But how do you reliably extract clean Maltese text, given all the challenges with doing so? The NOMOCRAT project seeks to do just that – extract Maltese text while leaving out errors.
A corpus is a large collection of text that is used for studying how language is used (for example, word frequencies) and for training computers to generate text. For Maltese, the largest public corpus is the MLRS Korpus Malti, which mostly consists of text collected from the web. However, there is a problem: a lot of text is extracted from PDFs by simply extracting the digital text from them.
Although PDFs contain copiable text, they are not designed to extract corpus-ready text. For example, paragraphs of text are interrupted by unrelated text such as figure captions, footnotes, page numbers, and so on. Columns can be merged and copied as if they were a single column, and characters can appear as different characters, such as Maltese diacritical characters (e.g. ‘ż’), being other characters under the hood, such as ‘\’, but with a font that makes them look like the Maltese character, and so on.
These problems, along with words being hyphenated and incorrectly inserted into the corpus as two pieces, and PDFs consisting of scanned pages with no copiable text, make extracting clean text from PDFs a challenge. But what if the text can be copied in the same way that a human would copy the text – visually?
Computers That Can Read
The New Open Maltese OCR Annotated Text, or NOMOCRAT, project is about creating a pipeline for extracting text from PDFs using computer vision techniques, namely:
- Document Layout Analysis (DLA) – Automatically recognising the different parts of a page.
- Optical Character Recognition (OCR) – Automatically recognising the text in an image.
The idea being that the different parts of the page, such as tables, titles, footnotes, and so on, are first identified using a DLA, and then the parts of interest are visually copied using an OCR.
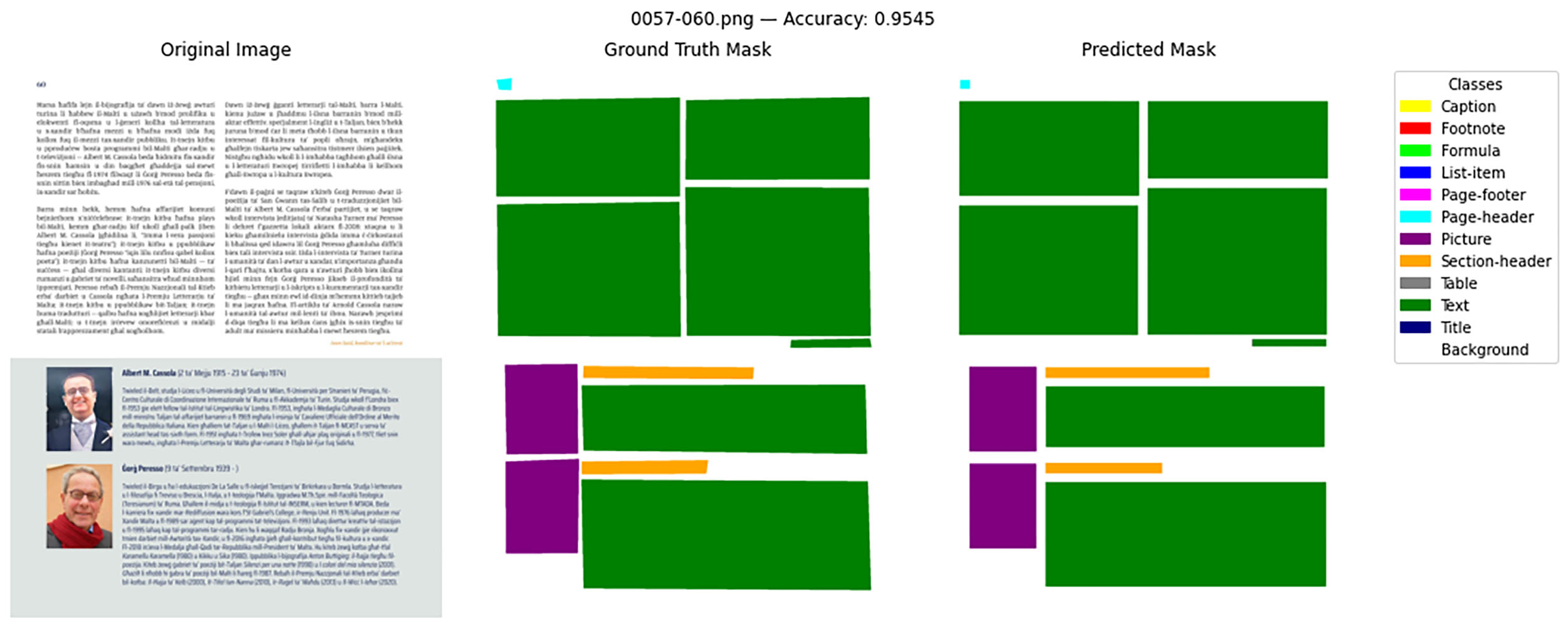
The first challenge was to create a dataset of these tasks to evaluate existing DLAs and OCRs on Maltese documents. Several Maltese-language PDFs were collected from websites, and the pages were extracted as images. Following this, the images were sampled and annotated manually. For the OCR data, every paragraph was marked, and the text was manually copied and fixed. For the DLA data, page regions were marked and labelled.
Subsequently, the NOMOCRAT team evaluated several downloadable DLA and OCR models (no online services were used). The DLA models performed very similarly, but for the OCR, Tesseract was by far the best model.
Finally, they assessed the performance of a pipeline integrating the best DLA and OCR for extracting corpus text from a page. The procedure was as follows:
- ignore any irrelevant parts (such as pictures, headers, and footers) with the DLA;
- use an OCR on the remaining parts;
- keep the main text separate from the captions and footnotes;
- use a reading order algorithm that was developed by the team to estimate the order of the paragraphs; and
- put all the paragraphs together into a single text.
The research team manually created a dataset of the expected outcome for each page after extraction to evaluate the success of their procedure.

A Good Start
Compared to using a typical tool for extracting text from a PDF, such as PyPDF, the team’s procedure extracts text that is five times closer to the desired outcome, though it remains about 10% inaccurate. They also had some success with improving the DLA and OCR by training them on their data, but did not have time to test them on the text extraction task.
From this project, NOMOCRAT’s main contribution is its datasets. They are also hosting a competition at DocEng26, where participants are invited to develop an even better OCR using paragraphs extracted from NOMOCRAT’s OCR data. For this reason, the full dataset will only be made public after the competition ends in July, to avoid leaking the test set used in the competition.
Follow the project page for updates!
The NOMOCRAT project was funded by Xjenza Malta’s Research Excellence Programme, project number REP-2024-057. The following are the people who worked on this project:
- Dr Marc Tanti, as principal investigator, Institute of Linguistics and Language Technology
- Prof. Alexandra Bonnici as co-investigator, Department of Systems & Control Engineering
- Dr Ing. Stefania Cristina as co-investigator, Department of Systems & Control Engineering
- Emma Fenech as Research Support Officer
- Vanya Gelfo as Research Support Officer
- Jamie Buttigieg as Research Support Assistant
- Isabelle Camilleri as Research Support Assistant




Comments are closed for this article!